
In recent days, thanks to the summer break taken by many customers, I had the opportunity to test some new tools and products that I had always wanted to try but never had the chance to. One of the tools on my list was Migrate While Active, option 2 of the DB2 Mirror product (5770DBM).
There are some differences between option 1 (the real DB2 mirror) and option 2 (Migrate While Active or MWA), there are some differences both from a technological point of view (option 1 requires RDMA technology while option 2 only requires TCP connectivity between the two systems) and from the point of view of the product’s purpose (option 1 provides high reliability on two active nodes, option 2 is not a high-reliability tool, it is used to migrate systems).
Now, the curiosity about this tool stems from the fact that one of the tasks we perform daily within my organisation is the design and completion of migrations from customer data centres to our data centre, and as everyone can imagine, the less Mr Business stops, the happier customers are, especially in a complex phase such as the migration of a production system.
With the aim of reducing machine downtime, I jumped at the new methodology released with level 27 of the DB2 Mirror group for 7.4, which effectively uses data replication technologies managed directly by the operating system without going through a shutdown for global (or partial) machine backup. So let’s have a look at the requirements:
- OS V7R4M0 (at the moment, this feature supposed to be planned in the autumn for newer releases)
- Group SF99668 level 27
- Empty target partition with same LIC level as production
- Some LPPs and open source packages (here the full list)
- Discrete amount of bandwidth to use for replication
Let’s get started! For my test, I cloned an internal production machine with a capacity of approximately 1.5TB of data, 1 Power 9 core, and 32GB of RAM. My goal was to replicate this machine from the primary datacentre to the datacentre we use for disaster recovery. The two datacentres are directly connected from a network perspective, so I had plenty of bandwidth available. Once the clone was created and updated with PTF, I was ready to start replicating. I also had to install another IBM i system with the *BASE option of product 5770DBM so that I could use the GUI.
Now, on the dr site, I created a partition of similar size and installed the LIC version that was also present on the production system (for this reason, I updated the ptfs on the initial clone, in order to use the latest LIC resave). Once the LIC installation is complete, we are ready to start the replication.
You need to access to the webgui (https://guiserver:2010/Db2Mirror) and also you need to click on “CONFIGURE NEW PAIR”, now we’ll choose Partition Mirroring:
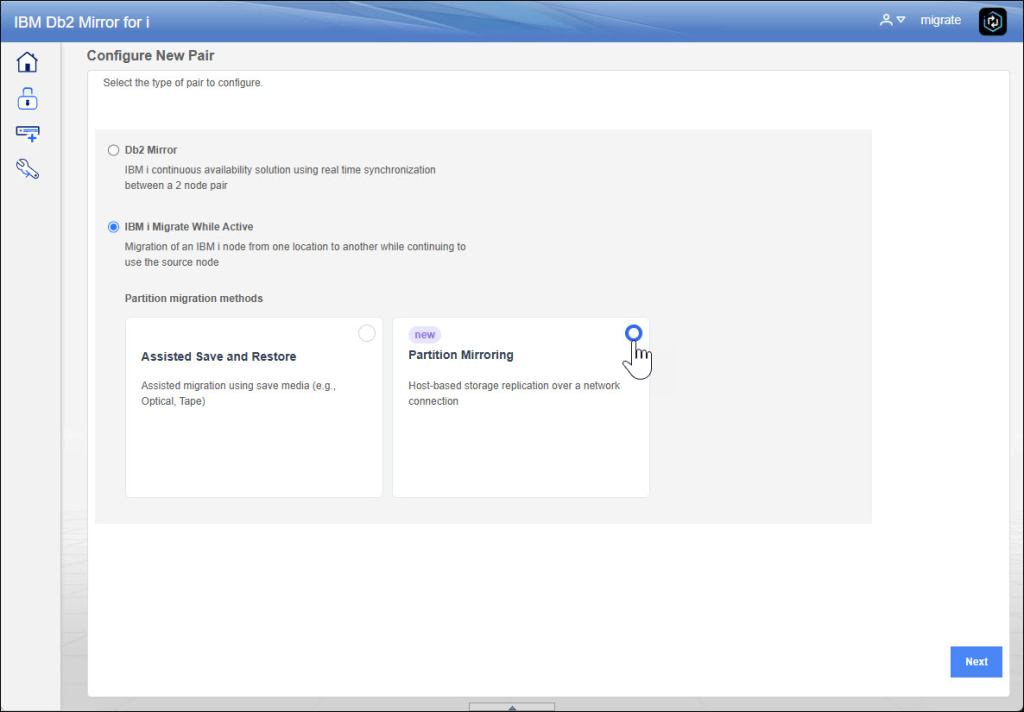
Once checked Partition Mirroring, we need to insert information about source node, these credentials is used to check if all requirements are fulfilled:
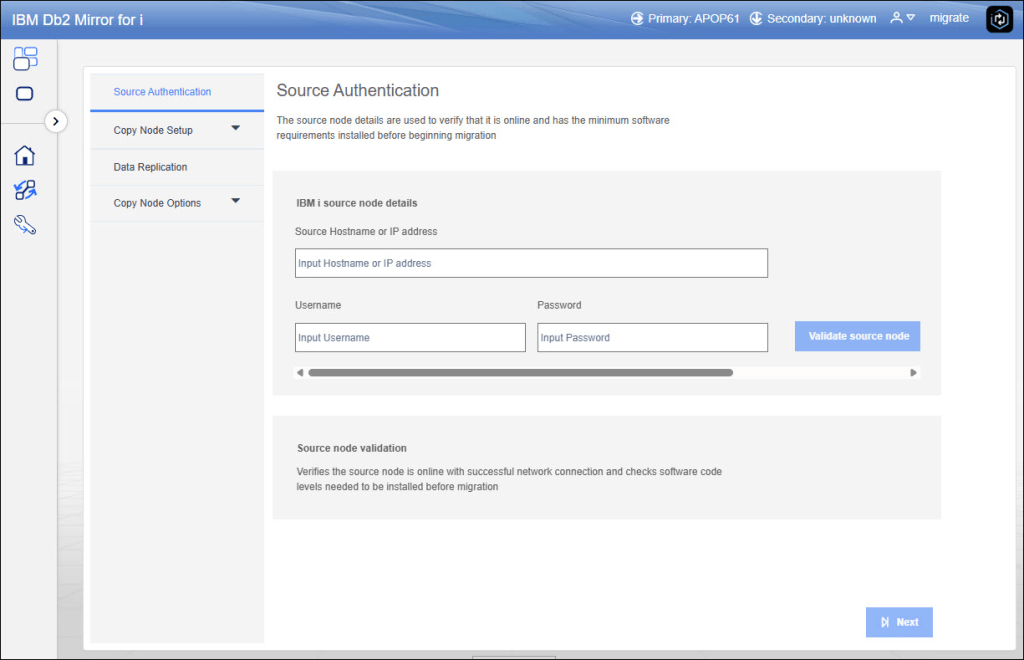
In my case, LIC has been already installed on the target node so you can proceed to the Service Lan Adapter from DST (here the full guide). When the adapter configuration is ended we can proceed in the wizard putting target ip address:
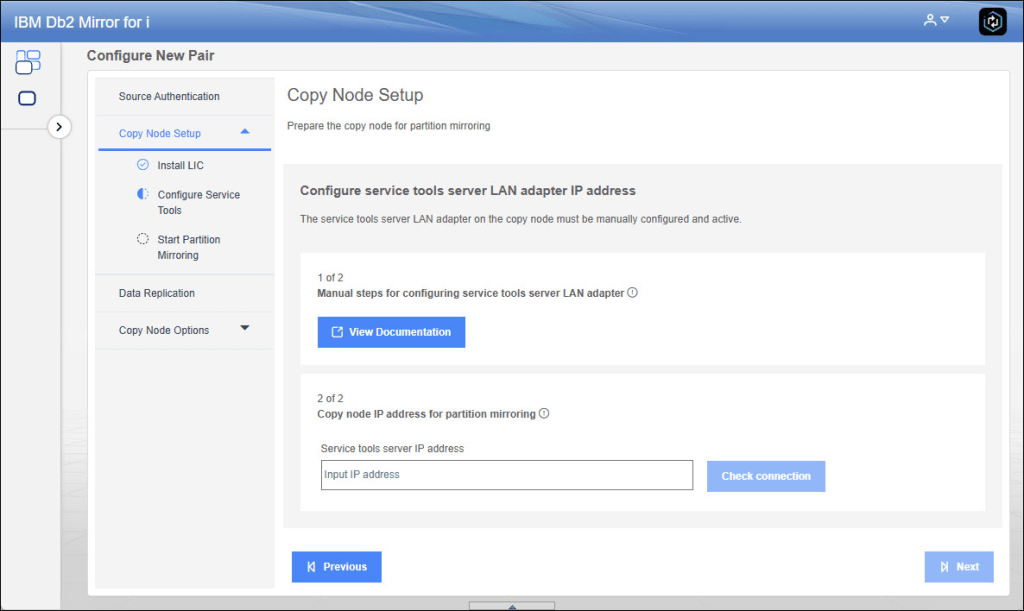
As you understand, in the target node there is no OS, no TCP services, it is a low level communication. In fact in the next step you need to generate a key from the GUI that allows source and target communication, this key should be inserted in a DST macro (here the full documentation).
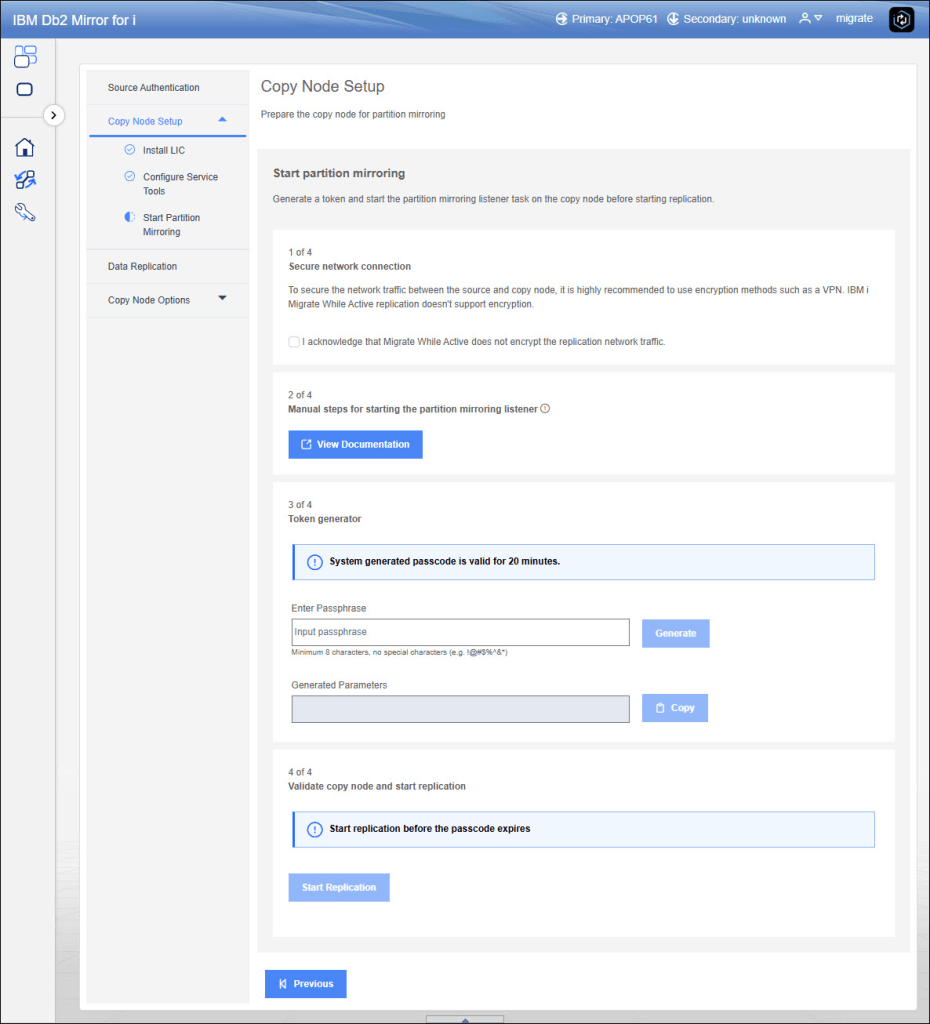
If you have already performed actions on the DST, we are able to start replication:
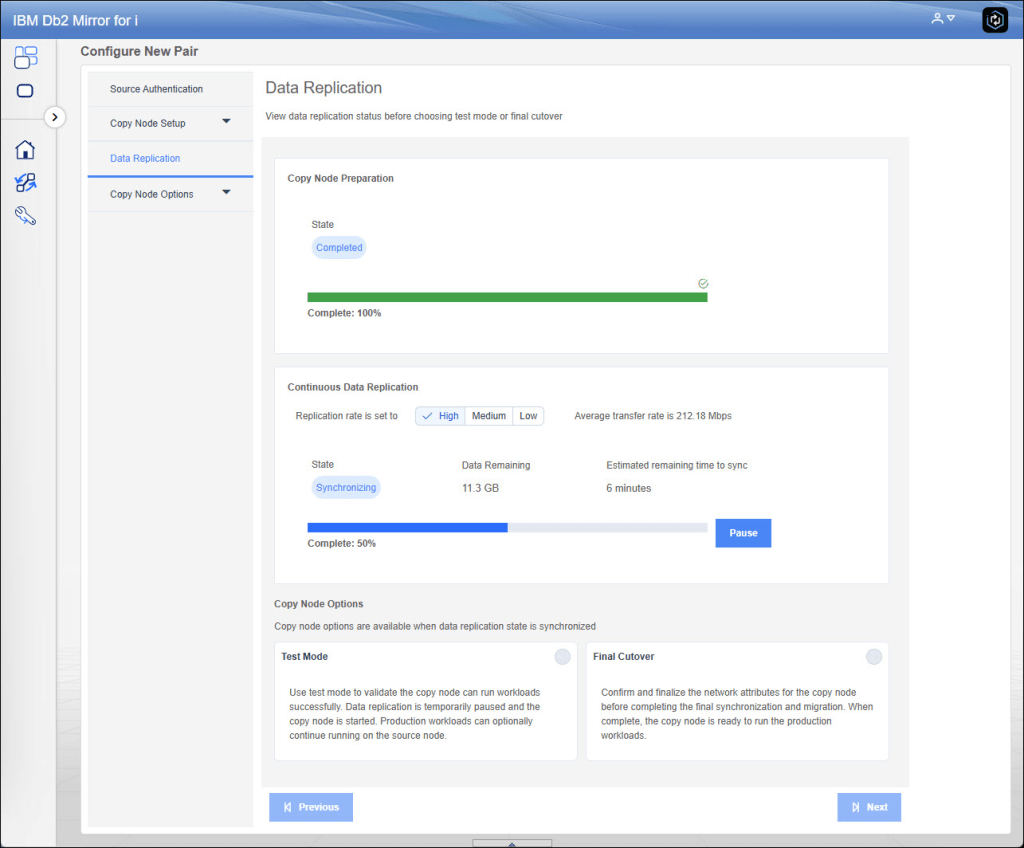
As you can imagine, at this point the sysbas synchronization phase begins, during which all data must be transferred and applied to the target replication system. As mentioned a few moments ago, this technology is only valid for sysbas; for iASP, the features already incorporated into PowerHA remain. The system replication is total, so it is not possible to partially replicate by indicating what to replicate and what not to replicate.
One of the real gems of this tool, however, is the ability to preview the consistency of the system. Once the systems are synchronized, it will be possible to activate a test mode in which replication will be suspended and both systems will track data modification activities: the source to know what to send to the target site and the target to know how to roll back the changes once testing is complete. The test mode will depend on the requirements of the various end users. It can be activated with a different network setup or with the same IP as production (clearly, at least the interface on the latter will have to be closed to avoid duplicate IPs). Once you are ready to perform the CUTOVER, disk writes to production will be suspended, pending transactions will be applied on the target, and then the target partition will be restarted with the specified network settings. In all phases you know how much time is required.
Unfortunately, this test did not provide me with any significant benchmarks. The machine was still a clone, and although the batches ran continuously, there were no interactive features or interfaces with other external systems, so the workload was not comparable to production. However, it was possible to migrate a system of approximately 1.5TB in about 6 hours. During those 6 hours of maximum priority replication (it is possible to specify priorities so as not to impact performance too much), the system was using 1 full core (Power9) and about 200mbps. In 6 hours, I would have been able to migrate my system to another datacentre, and the great thing is that all this without the initial downtime to make the backup… in fact, the only downtime is that of migration one. Clearly, this type of solution requires good computing power and bandwidth, which initially allows the complete system to be brought online and then keeps the two environments aligned.
And you, do you have opportunity to test this kind of software or related?
Andrea