I often find myself needing to run several commands in QSH, and I have now found an alternative way to do this compared to the classic bash scripts. Once again, SQL comes to our aid.
Now, using QSH in batch mode is very simple but requires a little attention. In our case, for example, we used two environment variables that can be extremely useful. The first is QIBM_QSH_CMD_OUTPUT. This variable allows you to define where to leave the output of the QSH session. In interactive mode, for example, the default is STDOUT, so when a command is executed in QSH, the panel opens. In our case, when submitting in batch mode, the easiest way is to generate a log file. The second variable, QIBM_QSH_CMD_ESCAPE_MSG, is also extremely useful and allows you to intercept errors that occur during the execution of a command in QSH. Otherwise, it would only generate an informational message in the job log stating that the exit status of the command is not 0.
First, I built a scalar function that took the command to be executed as a parameter and returned the result of the execution. The use case is when you need to execute a command that does not return any particular output. Here is an example:
As you can see, the first command works fine with rc 1, the second has an error and returns me -1.
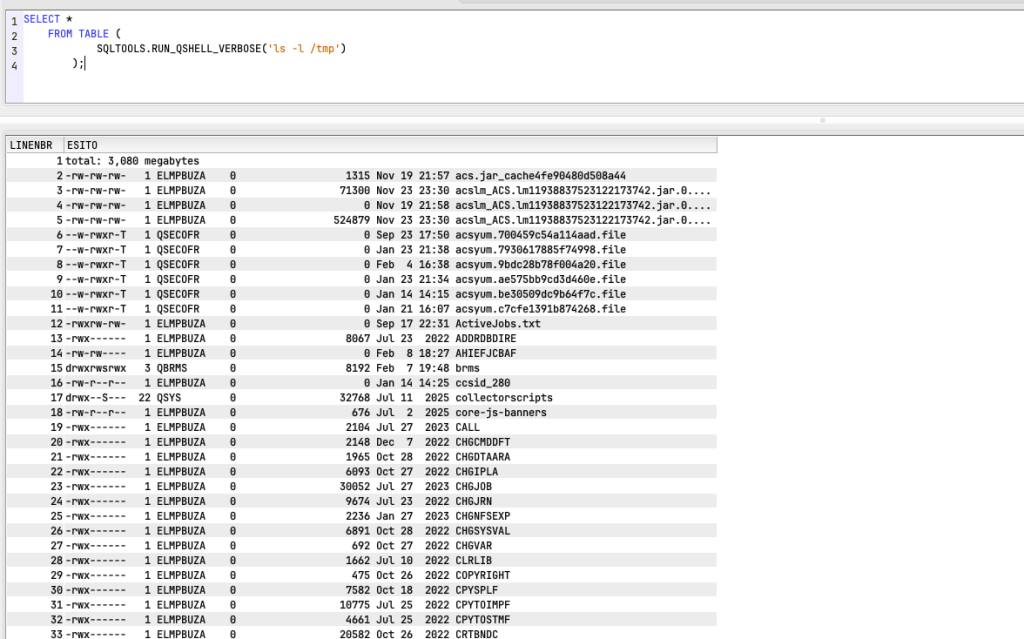
After that, I created a second function, which in this case returns a table. This allows you to return the result of a command if needed. Here is another fairly trivial example with ls -l:
As you can see, in this case returns me the list of objects that are in /tmp directory.
Some implementation notes… with regard to the above comments on environment variables, when the script starts, it checks for the existence of these environment variables. If they exist, it modifies them and then restores them at the end of execution. If they do not exist, it creates them and then removes them. As for the version with table function, in this case the output is generated in a temporary file under /tmp. This temporary file is read and its contents are inserted into a file in QTEMP. The output of the function is the contents of that file in QTEMP. Also note that in order to avoid clutter, the ifs file is deleted once its contents are transferred to QTEMP.
And you, have you ever needed to run a QSH command from SQL, perhaps because it was contained in a table, etc.?
As usual, the source code for the functions is available on my GIST at this link.
This week, a customer opened a ticket complaining that there were too many job logs on their system… this meant that when a user searched for their print job with WRKSPLF, they were inundated with a considerable number of job logs, making it difficult to find the relevant spool.
While I find the spool tool relatively convenient, I often see customers using OUTQs as archives. Let’s be clear: OUTQs are not archives! There are different tools that can perform that function. Moreover, for a sysadmin, the spool is an enemy of performance. Replication tools, for example, replicate one spool at a time. Last year, during the migration of an important customer, we found ourselves having to change the migration method due to poor performance in spool restores (and the customer had about 10 million of them).
Let’s get back to the matter at hand… now, the conditions that can cause a job to leave the log are:
4 0 *SECLVL, and here we need to investigate whether it is the jobd that passes this parameter when starting the job or whether it is modified later with CHGJOB
DSPJOBLOG OUTPUT(*PRINT), again, the configuration specified in the job is overridden by printing it with the execution of that command
SIGNOFF LOG(*LIST), applies only to interactive sessions and ensures that when the interactive session is closed, it leaves the job log
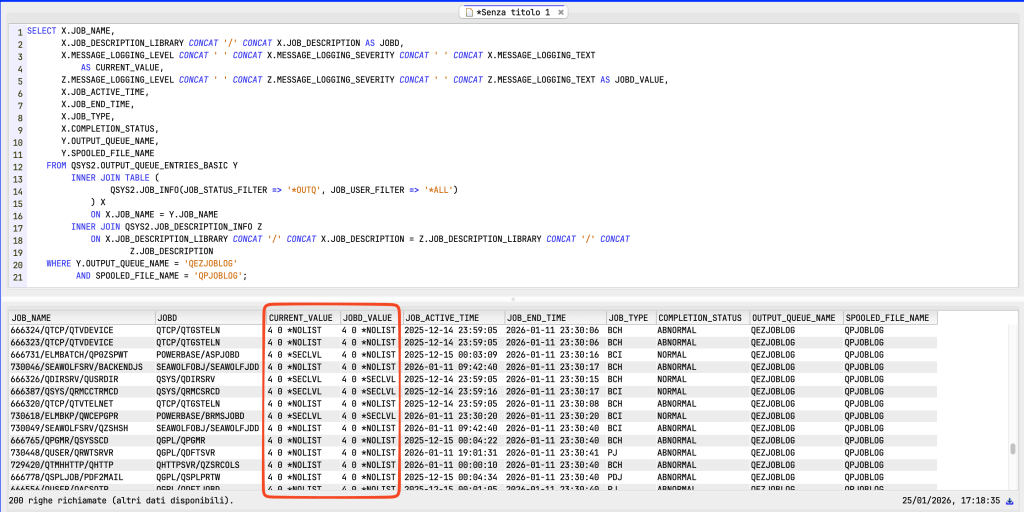
Now, how can I find out the possible cause for the job logs? SQL can be very useful in this case too. In the query example below (you can find the query on my Gist at the following link), I join the OUTPUT_QUEUE_ENTRIES_BASIC view (to extract only jobs with QPJOBLOG files in the QEZJOBLOG print queue) with the JOB_INFO view view (to extract the job execution parameters) and the JOB_DESCRIPTION_INFO view to see the logging parameters in the jobd.
Therefore, if both the jobd and the job have 4 0 *SECLVL as their logging parameter, it means that the job has maintained the settings defined by the jobd. If, on the other hand, the jobd reports a different value but the job maintains 4 0 *SECLVL, then it may mean that the job was submitted with a different parameter or that the job execution parameters were changed with the CHGJOB command. If the job value is also different from 4 0 *SECLVL and the job is a batch job, a DSPJOBLOG OUTPUT(*PRINT) has been performed. If it is interactive, the same reasoning is likely to apply, although it is possible to specify SIGNOFF LOG(*LIST).
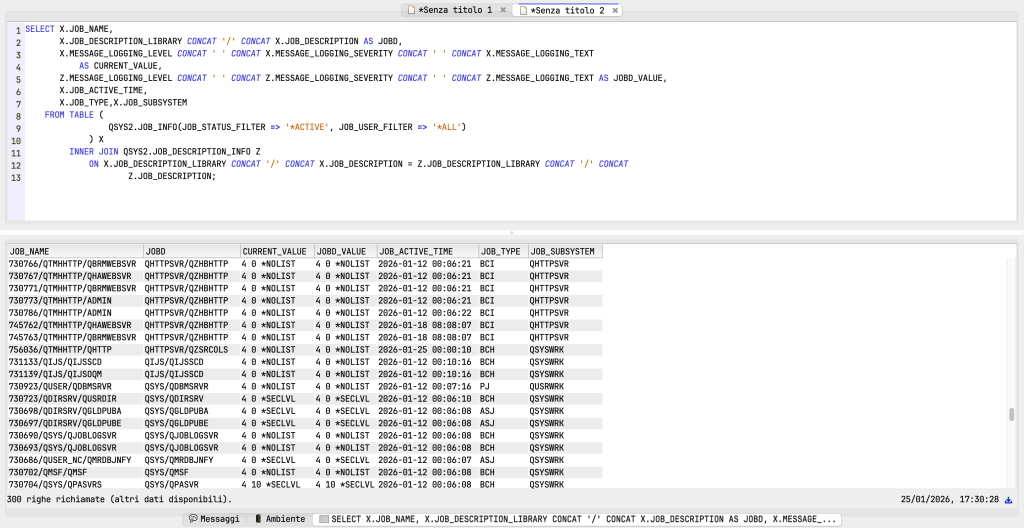
What if I want to analyse active jobs? Well, in this case, the query changes slightly, as there will most likely be no spool…
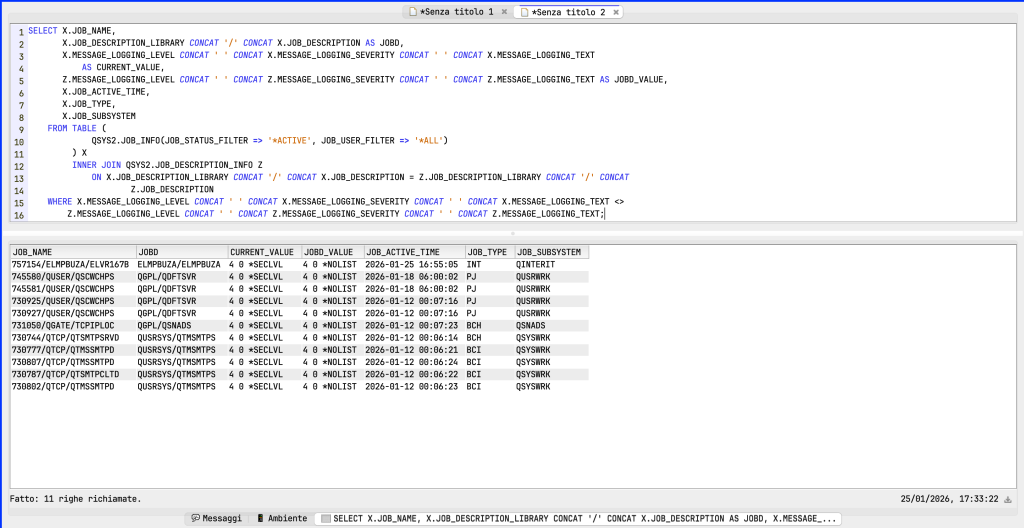
Or, if I want to check only job with defference between current settings and JOBD:
And you, have you ever considered using SQL for this type of analysis? I remind you that all the code is available on my GIST, which you can access at this link: https://gist.github.com/buzzia2001
During the Christmas holidays, between various lunches with relatives, an outing, and, of course, some rest, I had the opportunity to rework the Code4i FS extension a bit. It was very challenging in that it allowed me to learn a new language, TypeScript, and to learn about new aspects and SQL services of the IBM i operating system that I was completely unaware of before.
For those unfamiliar with it, this extension allows you to use and, in some cases, even manage additional objects beyond those traditionally supported by the standard extension. The aim is to improve the user experience for programmers (but not only them) by providing a single interface from which to work and get feedback, avoiding the need to switch frantically between applications. In addition, it is intended as a tool to help those who are just starting out and therefore have less experience, as the GUI greatly simplifies things.
New supported object types are 20, here you can find a list with the major features:
Data Queue
Send Message: Keyed/non-keyed support, UTF8 format, length validation, key validation
Clear Queue: Removes all messages with confirmation
View: Program info, bound modules with source details, bound service programs with signatures, exported procedures (SRVPGM only), SQL settings, optimization details, activation group
Query Definition
Translate to SQL: Converts Query/400 definitions to SQL format using RTVQMQRY command
View: SQL translation of query definition with proper table notation (LIB.FILE instead of LIB/FILE)
Note: Uses temporary source file and alias for extraction, automatically cleans up temporary objects
I would like to point out that this is not the final version; it is currently being reviewed by the Code4i team as the extension is part of that ecosystem. It is therefore possible that it may undergo further changes. However, it would be interesting for other users to be able to test it now in ALPHA so that any bugs can be checked and corrected, as well as to gather feedback on new features. So, if you want to be a tester, write a comment and I’ll get back to you with instructions.
System security is becoming one of the most important issues that IT managers have to deal with. This also applies to IBM i systems. In fact, the days when the only access to systems was via a terminal are long gone. Now systems are at the center of complex ecosystems that communicate with each other in various ways (REST APIs, remote commands, database queries, etc.).
One of the enabling factors for establishing secure communication is undoubtedly the use of SSL/TLS certificates. In a previous post, we saw how to download and import them using DCM or the tools provided by the QMGTOOLS library. For those who don’t know, internet standardization bodies have decided to gradually (but at the same time drastically) reduce the duration of these certificates. Consider that today the standard is about one year for the duration of SSL certificates, while in 2029 the target is to make them last ONLY 47 days…
As you can imagine, if a service uses these certificates and they expire in the meantime, this causes a blockage of services and, consequently, of the business connected to them. This is why it is essential to have a monitoring system that, beyond the expiration date, also provides visibility of the applications affected by the certificate change…
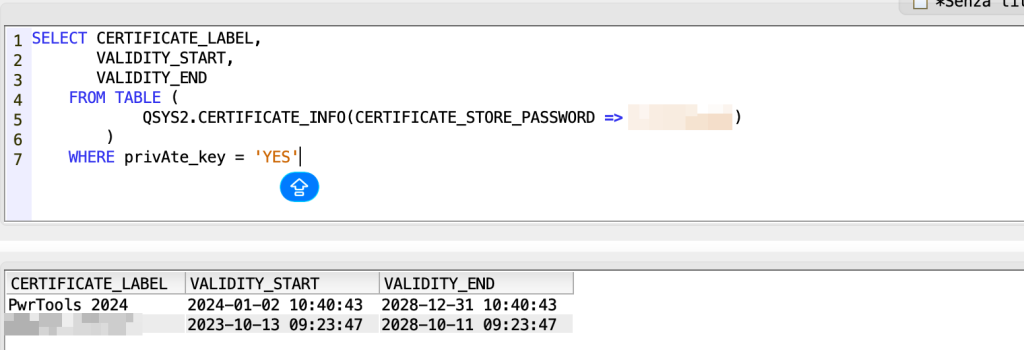
First, let’s extract the list of certificates with private keys (those for server or client applications that require authentication):
SELECT CERTIFICATE_LABEL, VALIDITY_START, VALIDITY_END FROM TABLE (QSYS2.CERTIFICATE_INFO(CERTIFICATE_STORE_PASSWORD => 'XXXXX')) WHERE private_key = 'YES'
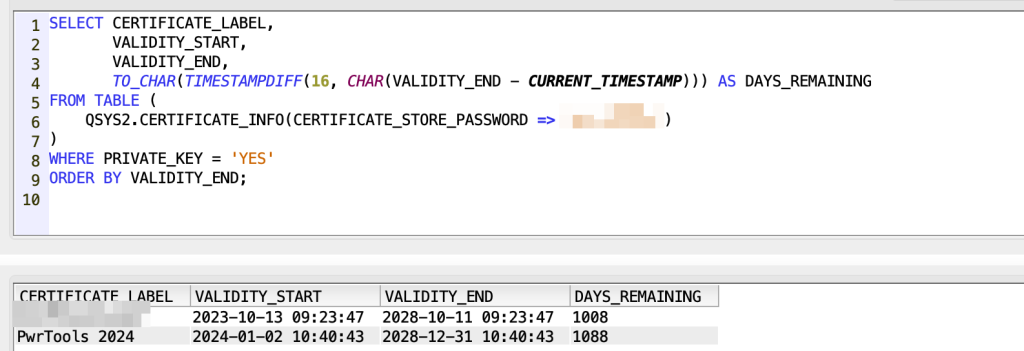
In this way you can also put a where condition on the days between current date and expiration date:
SELECT CERTIFICATE_LABEL, VALIDITY_START, VALIDITY_END, TO_CHAR(TIMESTAMPDIFF(16, CHAR(VALIDITY_END – CURRENT_TIMESTAMP))) AS DAYS_REMAINING FROM TABLE (QSYS2.CERTIFICATE_INFO(CERTIFICATE_STORE_PASSWORD =>’XXXXX’)) WHERE PRIVATE_KEY = ‘YES’ ORDER BY VALIDITY_END;
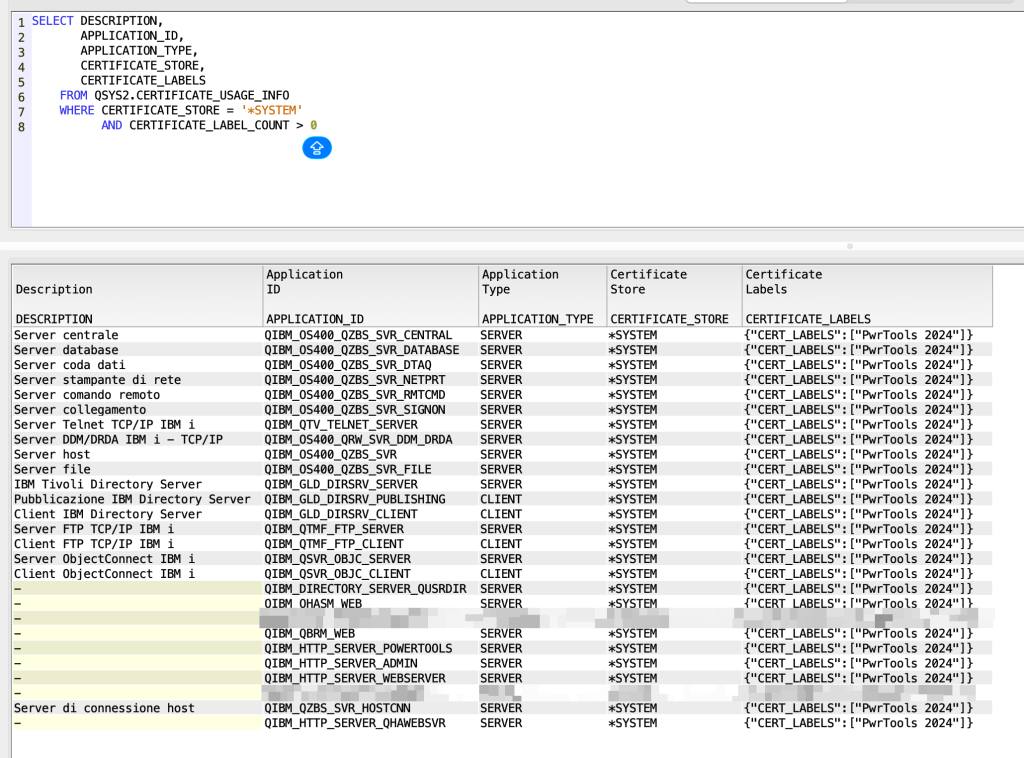
With this query you are able to extract every system service that is using SSL/TLS:
SELECT DESCRIPTION, APPLICATION_ID, APPLICATION_TYPE, CERTIFICATE_STORE, CERTIFICATE_LABELS FROM QSYS2.CERTIFICATE_USAGE_INFO WHERE CERTIFICATE_STORE = '*SYSTEM' AND CERTIFICATE_LABEL_COUNT > 0
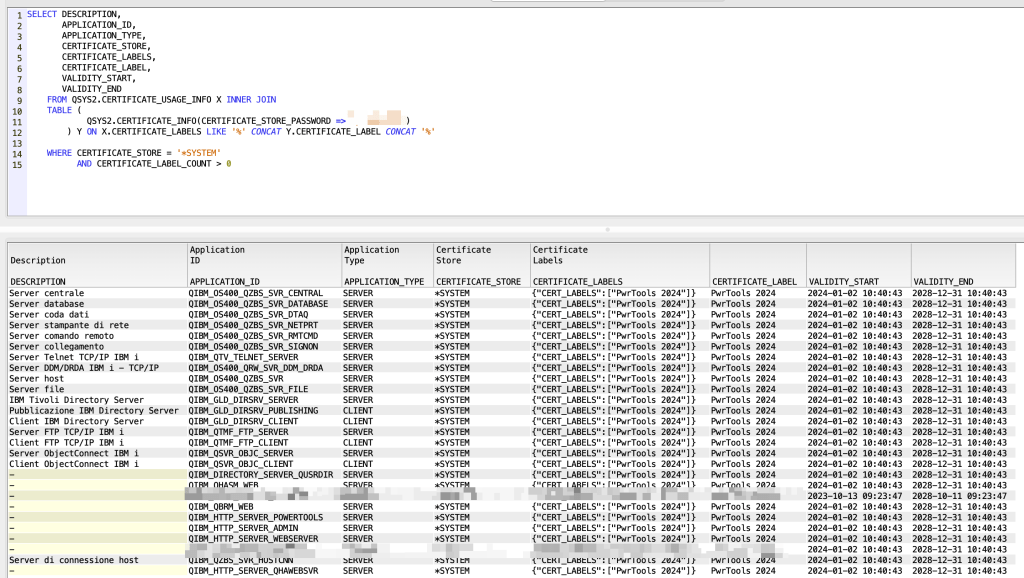
Now let’s print the applications and associated certificates:
SELECT DESCRIPTION, APPLICATION_ID, APPLICATION_TYPE, CERTIFICATE_STORE, CERTIFICATE_LABELS, CERTIFICATE_LABEL, VALIDITY_START, VALIDITY_END FROM QSYS2.CERTIFICATE_USAGE_INFO X INNER JOIN TABLE (QSYS2.CERTIFICATE_INFO(CERTIFICATE_STORE_PASSWORD => 'XXXXXX')) Y ON X.CERTIFICATE_LABELS LIKE '%' CONCAT Y.CERTIFICATE_LABEL CONCAT '%' WHERE CERTIFICATE_STORE = '*SYSTEM' AND CERTIFICATE_LABEL_COUNT > 0
And you, do you have any service with SSL enabled and a real certificate monitoring tool?
This week, the wait is finally over… a few weeks after signing up for the demo, BOB has finally arrived, and I have the chance to try it out in advance.
For those who are not yet familiar with it, BOB is a new IDE owned by IBM. It is not a completely new IDE; in fact, for those who regularly use Visual Studio Code, the environment will be very familiar, because BOB is based on it. The reasons for this choice are quite simple to identify. First, compared to RDi, Visual Studio Code is much lighter and more performant, as well as being significantly more modular. Second, Visual Studio Code is a standard IDE, convenient for any programming language. In fact, there are extensions for virtually any language, which makes development on IBM i much closer to industry standards.
Now, if BOB were just a copy-and-paste version of VSCode, it would be useless… The real added value of BOB is its native integration with artificial intelligence. In fact, when you open it for the first time, you immediately notice the prompt for interacting with the agent. In this case, compared to other competitors, the artificial intelligence offered here is based on the aggregation of several models, so you have a complete stack that allows you to respond to very different needs. Moreover, as you can imagine, since BOB is from IBM, it is well-trained in all IBM languages, such as RPG.
Now, let’s talk about my experience… as soon as it arrived, I put it to work on one of my Java projects. It’s actually the backend of an HTTP portal that we use to provide services to our customers. First, I asked it to generate some documentation (yes, I don’t like writing documentation), and in about an hour, it wrote all the javadoc for over 140 classes. In addition to writing the documentation, I was pleased to note that it is able to suggest possible improvements to the code. In this case, for example, it highlighted the possibility of SQL injection:
This is just an example; it also suggests possible code refactoring.
Now, let’s talk about evaluations… We are only at the beginning, and I haven’t been able to test it sufficiently yet, but let’s say that expectations are very high. As for the documentation I asked him to write for me, it seems to be very focused on the subject… I still have some doubts about code generation, but I also believe that it should definitely be an aid (and it is) to the programmer, not a replacement. Another definitely positive thing is that it asks for permission before accessing/modifying a file, showing all the changes in a preview and explaining them. On the other hand, the demo comes with a $20 budget, and I’ve already burned through about $14 just with the documentation I asked for, which means I can’t really test it thoroughly.
From my point of view, the next steps concern the RPG world, i.e., the automatic generation of test cases and code documentation. This is because, in addition to the IDE, it is also possible to invoke BOB’s APIs from the CLI, meaning it can be integrated into automatic compilation/release pipelines.
For completeness, I am attaching the link to sign up for the BOB demo in case you haven’t already done so: https://www.ibm.com/products/bob
Have you had the opportunity to test and use artificial intelligence tools in your work? What do you think?