It is quite common to have customers with specific backup requirements, such as changing the expiration date of the tape used based on the day of the month or year for tax purposes. For this reason, it is always complicated to have standard jobs or calendars with a predefined retention period.
So if a standard approach is not feasible, we go for a custom approach… Now SQL and BRMS come to our aid. In fact, there are several SQL services compatible with 5770BR1, and even more with 5770BR2.
Now, let’s proceed with creating an SQL procedure that modifies the media class, move policy, and retention for the tapes used in the job in which it is launched. Then, let’s extract the queries we need:
Find the current job: select job_name from TABLE (QSYS2.ACTIVE_JOB_INFO(DETAILED_INFO => 'NONE', JOB_NAME_FILTER => '*'))
Find tapes and creation date: select volume_Serial, created from qusrbrm.media_info
Find job that changes a tape: select tmcvsr, TRIM(LPAD(TMJNBR, 6, '0') CONCAT '/' CONCAT TRIM(TMUSER) CONCAT '/' CONCAT TRIM(TMCJOB)) from qusrbrm.qa1amm
Now, let’s create a query that give us serial number and the new expiration date: SELECT VOLUME_SERIAL, CASE WHEN RETENTION <> 9999 THEN TO_CHAR(CREATED + RETENTION DAYS, 'ddMMyy') ELSE 'PERM' END FROM QUSRBRM.MEDIA_INFO INNER JOIN QUSRBRM.QA1AMM ON VOLUME_SERIAL = TMCVSR INNER JOIN TABLE (QSYS2.ACTIVE_JOB_INFO(DETAILED_INFO => 'NONE', JOB_NAME_FILTER => '')) ON TRIM(JOB_NAME) = TRIM(LPAD(TMJNBR, 6, '0') CONCAT '/' CONCAT TRIM(TMUSER) CONCAT '/' CONCAT TRIM(TMCJOB))
So, in our case, we have RETENTION that is a variable that contains the number of days to maintain the tape active, 9999 is a special value that in my case means that the tape should not have an expiration date.
At this point, it’s all very easy. I just have to loop through the result set and run the CHGMEDBRM command with the correct parameters for media class, move policy, and retention.
As usual, you can find the source code for the procedure, download it, and edit it as you wish.
I often find myself in a situation where I have several different systems and need to extract data from all of them by running queries from a single partition. Well, there is a DB2 for i function that allows you to run SELECT SQL on remote machines.
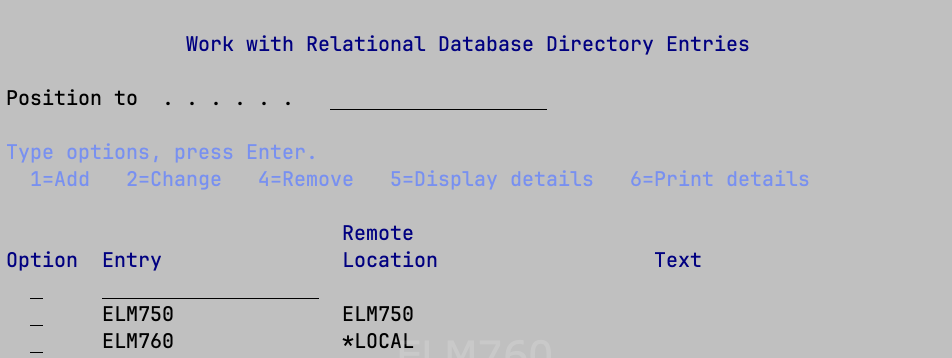
What do we need? First of all, it is essential that the database of ‘remote’ machines be registered in the central system’s database address book. To verify that this is the case, use the command WRKRDBDIRE and, if necessary, add 1 (or use the command ADDRDBDIRE):
In my example, I am working on the ELM760 machine and trying to connect to the ELM750 machine.
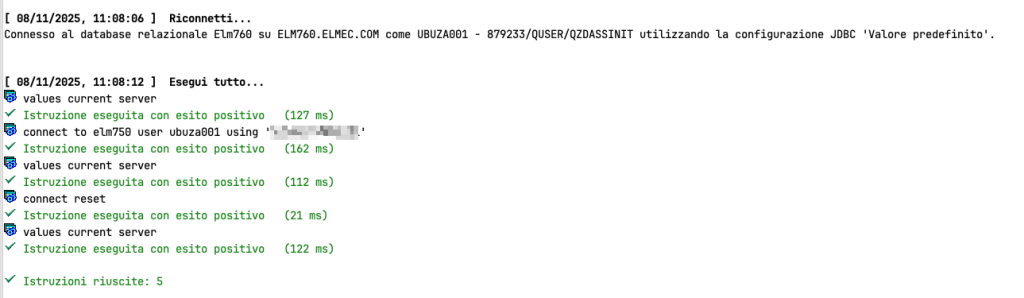
Traditionally, it was already possible to connect from one database to another using the CONNECT TO remote database name statement, but in this case, you opened a stable connection that was closed only when the SQL job was closed or, in general, with the CONNECT RESET statement:
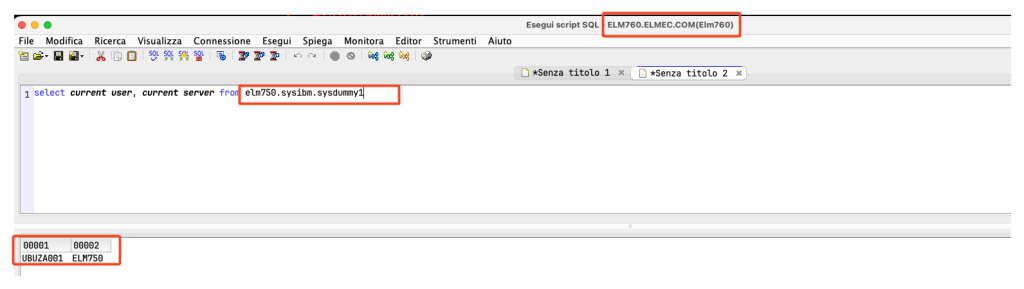
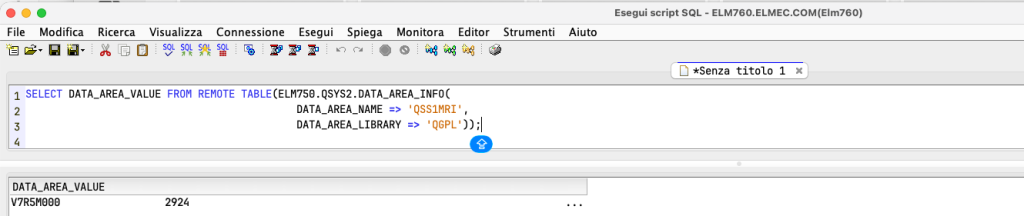
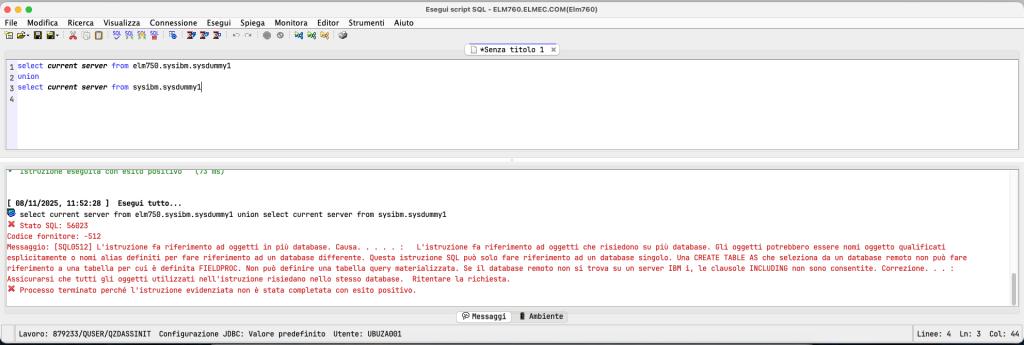
There is another, more convenient way, which is to use REMOTE TABLES. In fact, it is possible to query tables from another system in a single statement. Let’s look at an example:
As you can see, connected to ELM760, I am simply interrogating ELM750. This also works for table functions:
Now, in order for everything to work correctly, it is necessary to define entries at the GO CMDAUTE authentication information level. In this case, it is possible to set up specific authentication for each target lpar or (although I do not recommend this for security reasons) generic authentication for the QDDMDRDASERVER server (clearly only applicable to the user to whom the authentication applies).
The only structural limitation is the inability to join objects from two different databases, so for example I cannot join (or merge) objects that come from the local database and the remote database:
And you, have you ever tried remote tables in IBM i?
A few days ago, a customer opened a case with me because he couldn’t understand the origin of the locks that were occurring on certain objects. In fact, this lock condition was causing problems for the application procedures, which clearly found the files busy and were unable to operate on them.
There are various solutions to this issue, but the one that seemed most convenient and functional to me was to use our friend SQL.
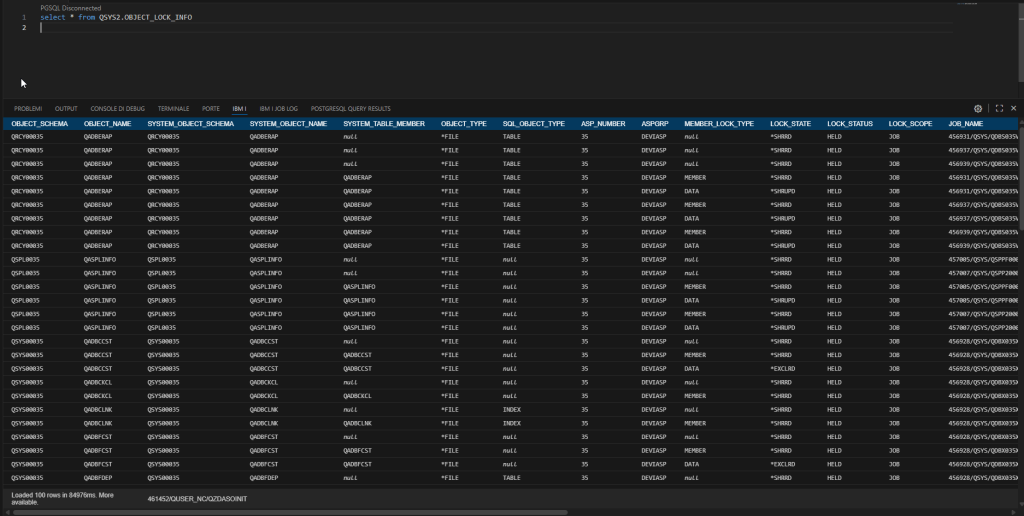
In the tool we will implement today, we will use the QSYS2.OBJECT_LOCK_INFO system view. This view returns a series of very useful information, such as the object being locked, the job that placed the lock, and the type of lock. However, it can also return very detailed information, such as the procedure/module and the statement.
Let’s look at an example of a query on this view without any filters: select * from QSYS2.OBJECT_LOCK_INFO
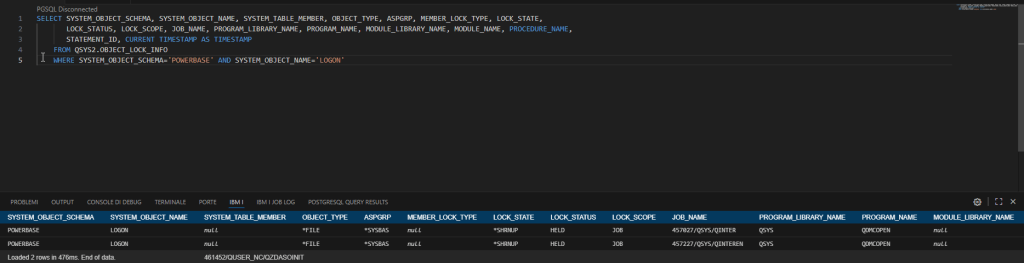
As you can see, it gives us a lot of information. Let’s go back for a moment to the customer’s primary need, which is to understand who placed blocks on a specific object and when, so we’ll start modifying the query. In this case, we’ll take less information, so I’ll select only a few fields: SELECT SYSTEM_OBJECT_SCHEMA, SYSTEM_OBJECT_NAME, SYSTEM_TABLE_MEMBER, OBJECT_TYPE, ASPGRP, MEMBER_LOCK_TYPE, LOCK_STATE, LOCK_STATUS, LOCK_SCOPE, JOB_NAME, PROGRAM_LIBRARY_NAME, PROGRAM_NAME, MODULE_LIBRARY_NAME, MODULE_NAME, PROCEDURE_NAME, STATEMENT_ID, CURRENT TIMESTAMP AS TIMESTAMP FROM QSYS2.OBJECT_LOCK_INFO WHERE SYSTEM_OBJECT_SCHEMA='XXXXXX' AND SYSTEM_OBJECT_NAME='XXXXX'
In my example, I took the display file for my system signon.
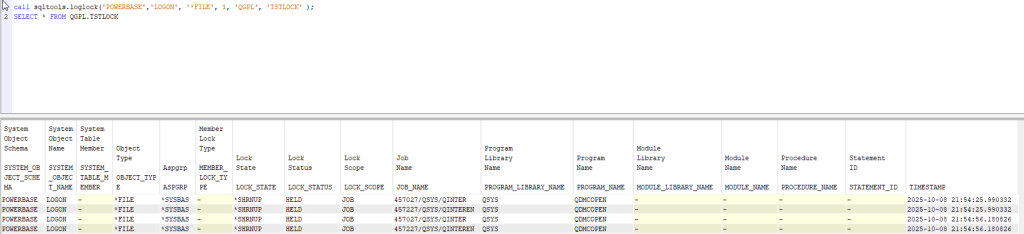
Okay, now that I’ve written the basic query, I’m ready to start the procedure.
Input parameters
Library name
Object name
Object type
Analysis duration
Analysis output file library
Analysis file name
Procedure body: first, I create the template file (the create table with no data) that I will use later to make all the entries I see. After that, I cycle until I have reached the time required for the analysis passed as a parameter. During this cycle, I insert the data extracted directly with the select into the temporary file I created earlier. I chose to run the analysis every 30 seconds, but feel free to change this time. Once I have reached the time I set, I copy all the output to the file that I passed as a parameter to the procedure
Calling the procedure: you can call it from RUN SQL SCRIPTS/STRSQL/VS CODE/RUNSQL, here you can find an example, let’s consider that if you want to run this analysis for a long time, is better to submit it in batch.
You need to be carefull! The query that I wrote works on every release >=7.5 because of the where statement. As you can see it’s quite complicated, and this kind comparison in where clause is not supported on older release, so, as I said a lot of time, PLEASE STAY CURRENT.
A few articles ago, we talked about the native integration of the syslog format within IBM i. We also looked at two SQL services (the history log and the display journal) that were able to generate data in this format in a simple way.
Today, in this article, I propose a possible implementation of a SIEM, which, starting from the logs on the IBM i system, feeds a Grafana dashboard. For those unfamiliar with Grafana, this tool is one of the leaders in interactive data visualization and analysis. It has native connectors with a wide range of different data sources, and can natively perform alert functions on the metrics being monitored.
The downside is that there is no DB2 datasource (at least in the free version). In our scenario, we chose to rely on a PostgreSQL instance running on AIX, which allowed us to build the dashboard with extreme simplicity.
In fact, our infrastructure consists of one (or more) IBM i partitions that contain all the source data such as JRNRCV, history logs, etc., a small Python script that queries the systems using the two specific views, and the collected data is then sent to a PostgreSQL database, which is then queried by dashboards built on Grafana for analysis purposes.
Below you will find the Python code written:
script information: this script can run directly on IBM i, but in fact, in an environment where there are several machines, it can be run from a centralized host. The only installation required is that of the ODBC driver, but there is a wealth of supporting documentation. In our case, there is a configuration file that contains both the database connection information and the host master data. The script can be invoked by passing LOG as a parameter (in which case the DSPLOG data will be analyzed) or JRN (in which case the QADUJRN entries will be looked at). Another parameter is the list of msgids of interest (valid in the case of LOG) or the type of entry (in the case of JRN), which is also supported as a value *ALL
getQhst: this function extracts entries with the msgid specified as a parameter. In fact, the extraction checks the last entry in the dsplog and reads all entries from the last extraction to the last entry detected now
getJrn: this function extracts entries from the system audio log. Again, the tool keeps track of the last entry read
As you can see, the extracted data is then dumped directly into a PostgreSQL table.
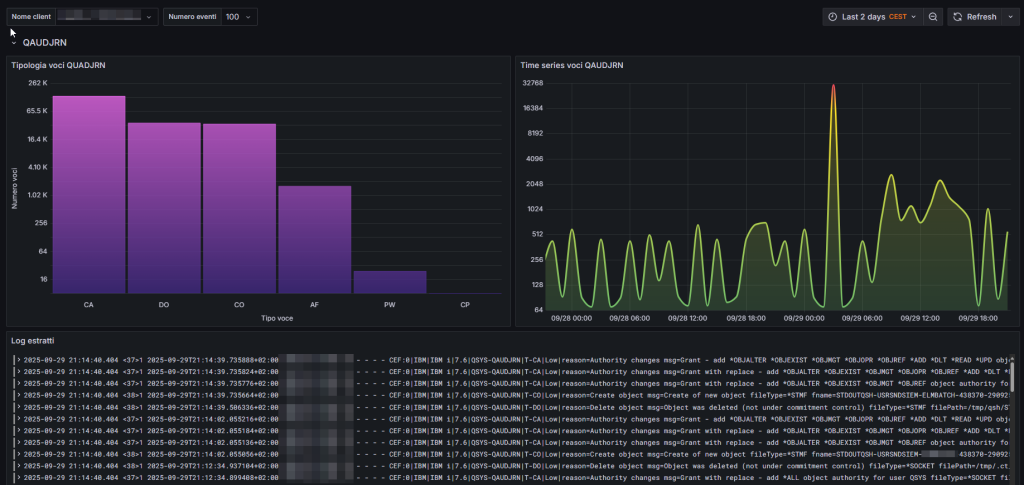
Below is the dashboard I built on Grafana:
As you can see, there is fairly basic information, a graph showing the types of entries and their counts, a graph showing the occurrence of events on different days, and finally the extraction of events in syslog format. The same dashboard is also available for the history log.
This week, I received a request from a customer to create a batch procedure that would restore files from the production environment to the test environment without transferring members due to disk space limitations. It seemed like a simple task, as the operating system allows this without any problems using the native RSTOBJ command thanks to the FILEMBR((*ALL *NONE)) parameter:
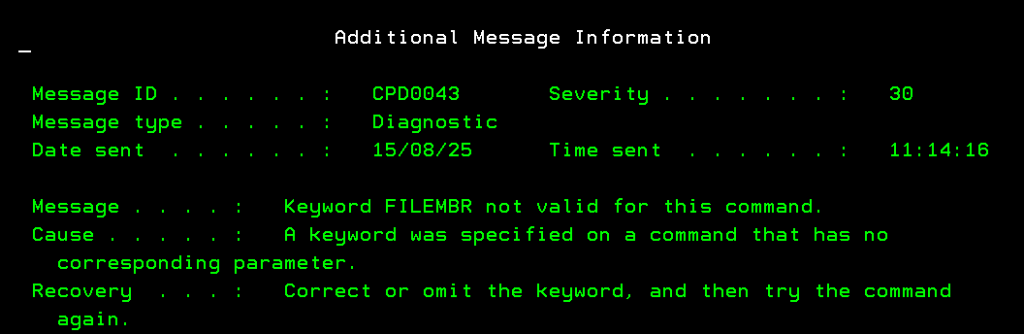
As mentioned above, it seemed simple, but the BRMS commands do not support this functionality. Let’s look at the RSTOBJBRM command, for example… If I try to pass it the parameter name, I get this error, precisely because the parameter does not exist in this case:
When talking to IBM support, I was told that the only solution at the moment to achieve my goal of restoring without members was to concatenate the native command with the information contained within the BRMS DB. This gave me the idea of creating a simple SQL procedure that would allow me to achieve my goal. Clearly, it was also feasible in other languages; I could have achieved the same result with an RPG programme. The choice of SQL was dictated by the need to find a quick alternative that did not require a great deal of development effort.
Let’s start with what we need… Let’s assume that the list of objects to be restored and the library in which they are located are passed as parameters, and let’s also assume that the library in which the restoration is to be performed is also passed as a parameter to the function. Now, what we need to calculate are the tape on which they are saved, the sequence (although we could use the *SEARCH parameter) and the device to be used for the restore.
Now, if you are using product 5770BR2 (with the most recent PTF), extracting this information is quite simple. In fact, there is a view in QUSRBRM called backup_history_object that returns information about the various saved objects. Alternatively, if you are using 5770BR1, you will need to query the QA1AHS file.
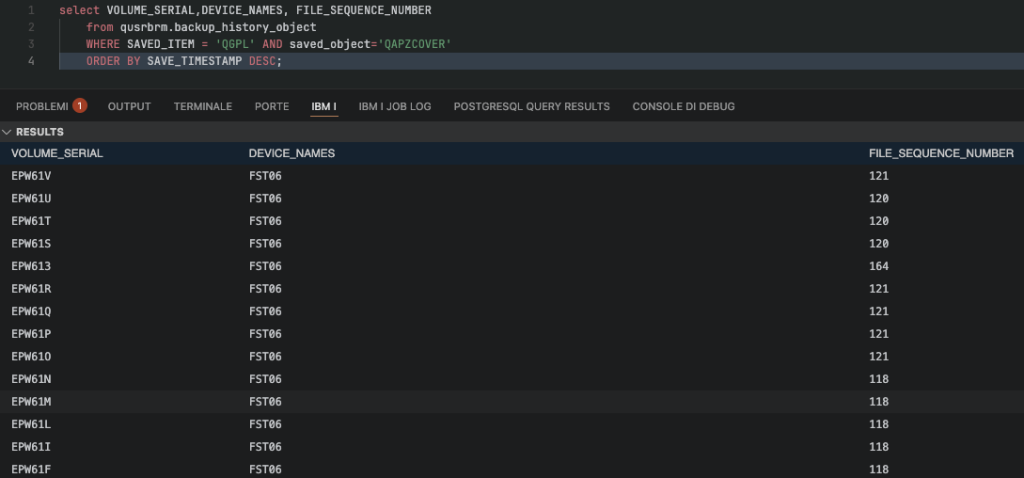
For example, we want to find media information for objects in QGPL (I will use QAPZCOVER as example)…
With 5570BR2 the SQL statement is: select VOLUME_SERIAL,DEVICE_NAMES, FILE_SEQUENCE_NUMBER from qusrbrm.backup_history_object WHERE SAVED_ITEM = 'QGPL' AND saved_object='QAPZCOVER' ORDER BY SAVE_TIMESTAMP DESC
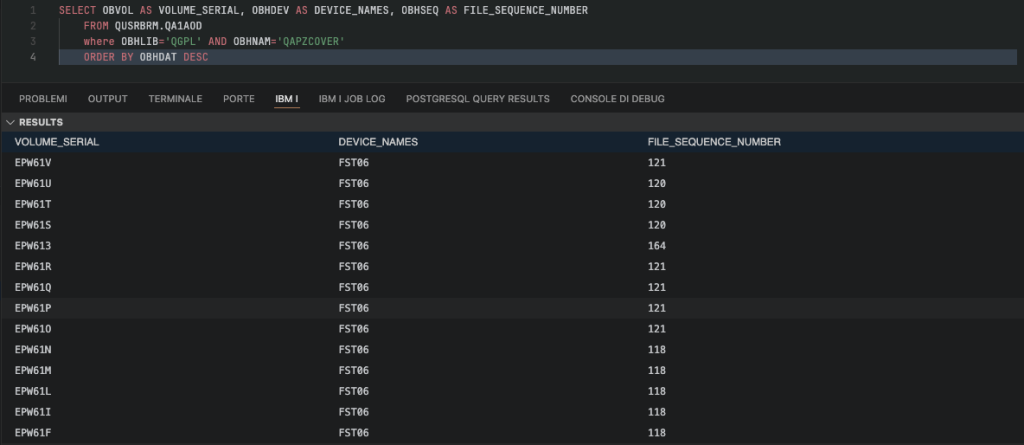
If you are using 5770BR1: SELECT OBVOL AS VOLUME_SERIAL, OBHDEV AS DEVICE_NAMES, OBHSEQ AS FILE_SEQUENCE_NUMBER FROM QUSRBRM.QA1AOD where OBHLIB='QGPL' AND OBHNAM='QAPZCOVER' ORDER BY OBHDAT DESC
As you can see, the result is the same regardless of which of the two queries you use.
Now, in my case, I needed the most recent save, so I applied a LIMIT 1 in my function, sorting in descending order by save date (so I inevitably get the most recent save). If you also want to parameterise the date, you simply need to add a parameter to the procedure and add a condition to the WHERE clause.
Now we are ready to create our procedure: in the first stage we will create RSTOBJ command retrieving data from QUSRBRM, after that we will use SYSTOOLS.LPRINTF to write command executed on the joblog and after that we will execute command using QSYS2.QCMDEXC procedure. In my case, the RSTLIB parameter is optional, by defualt is *SAVLIB:
SET PATH "QSYS","QSYS2","SYSPROC","SYSIBMADM" ;
CREATE OR REPLACE PROCEDURE SQLTOOLS.RSTNOMBR2 (
IN OBJLIST VARCHAR(1000) ,
IN LIB VARCHAR(10) ,
IN RSTLIB VARCHAR(10) DEFAULT '*SAVLIB' )
LANGUAGE SQL
SPECIFIC SQLTOOLS.RSTNOMBR2
NOT DETERMINISTIC
MODIFIES SQL DATA
CALLED ON NULL INPUT
SET OPTION ALWBLK = *ALLREAD ,
ALWCPYDTA = *OPTIMIZE ,
COMMIT = *NONE ,
DECRESULT = (31, 31, 00) ,
DYNDFTCOL = *NO ,
DYNUSRPRF = *USER ,
SRTSEQ = *HEX
BEGIN
DECLARE CMD VARCHAR ( 10000 ) ;
SELECT
'RSTOBJ OBJ(' CONCAT TRIM ( OBJLIST ) CONCAT ') SAVLIB(' CONCAT TRIM ( LIB ) CONCAT ') DEV(' CONCAT TRIM ( OBHDEV ) CONCAT ') SEQNBR('
CONCAT OBHSEQ CONCAT ') VOL(' CONCAT TRIM ( OBVOL ) CONCAT ') ENDOPT(*UNLOAD) OBJTYPE(*ALL) OPTION(*ALL) MBROPT(*ALL) ALWOBJDIF(*COMPATIBLE) RSTLIB('
CONCAT TRIM ( RSTLIB ) CONCAT ') DFRID(Q1ARSTID) FILEMBR((*ALL *NONE))'
INTO CMD
FROM QUSRBRM.QA1AOD WHERE OBHLIB = TRIM ( LIB ) ORDER BY OBHDAT DESC LIMIT 1 ;
CALL SYSTOOLS . LPRINTF ( TRIM ( CMD ) ) ;
CALL QSYS2 . QCMDEXC ( TRIM ( CMD ) ) ;
END ;
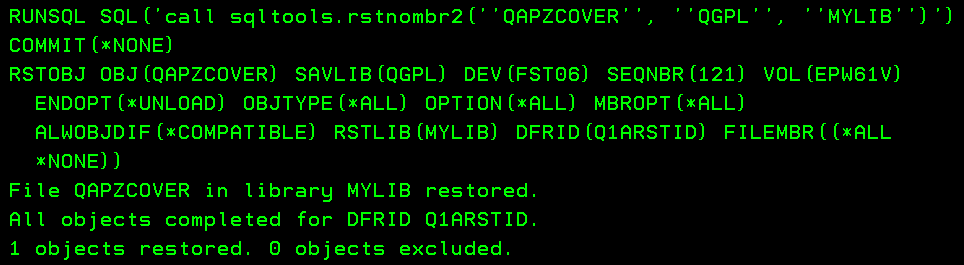
Ok, when we have created this procedure we are also ready to test it… From 5250 screen you can use this command: RUNSQL SQL('call sqltools.rstnombr2(''QAPZCOVER'', ''QGPL'', ''MYLIB'')') COMMIT(*NONE)
This is the result:
If you put this command in a CL program you are able to perform this activity in a batch job. Also in this way you are able to make the restore from systems in the same BRMS network if they are sharing media information, in that case you should query QA1AHS instead because object detail is not shared.
Syslog, short for System Logging Protocol, is one of the cornerstones of modern IT infrastructures. Born in the early days of Unix systems, it has evolved into a standardized mechanism that enables devices and applications to send event and diagnostic messages to a central logging server. Its simplicity, flexibility, and widespread support make it indispensable across networks of any scale.
At its core, Syslog functions as a communication bridge between systems and administrators. It allows servers (also IBM i partitions), routers, switches, and even software applications to report what’s happening inside them—be it routine processes, configuration changes, warning alerts, or system failures. It is also possible that these messages are transmitted in real time to centralized collectors, allowing professionals to stay informed about what’s occurring in their environments without needing to inspect each machine individually.
This centralized approach is critical in environments that demand security and reliability. From banks to hospitals to government networks, organizations rely on Syslog not just for operational awareness but also for auditing and compliance. Log files generated by Syslog can help trace user activities and identify suspicious behavior or cyberattacks. That makes it an essential component in both reactive troubleshooting and proactive monitoring strategies.
So, in IBM i there al least three places in which you are able to generate Syslog.
The first place where you can extract syslog format is the system log. The QSYS2.HISTORY_LOG_INFO function allows you to extract output in this format. In my example, I want to highlight five restore operations performed today: SELECT syslog_facility, syslog_severity, syslog_event FROM TABLE (QSYS2.HISTORY_LOG_INFO(START_TIME => CURRENT DATE, GENERATE_SYSLOG =>'RFC3164' ) ) AS X where message_id='CPC3703' fetch first 5 rows only;
By changing the condition set in the where clause it is possible to work on other msgids that could be more significant, for example it is possible to log the specific msgid for abnormal job terminations (since auditors enjoy asking for extraction on error batches).
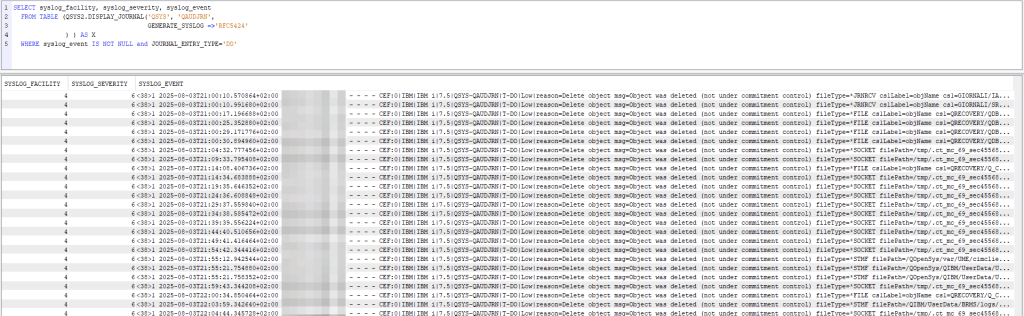
The second tool that could be very useful is the analysis of journals with syslog, in fact the QSYS2.DISPLAY_JOURNAL function also allows you to generate output in syslog format. In my example, I extracted all audit journal entries (QSYS/QAUDJRN) that indicated the deletion operation of an object on the system (DO entry type): SELECT syslog_facility, syslog_severity, syslog_event FROM TABLE (QSYS2.DISPLAY_JOURNAL('QSYS', 'QAUDJRN',GENERATE_SYSLOG =>'RFC5424') ) AS X WHERE syslog_event IS NOT NULL and JOURNAL_ENTRY_TYPE='DO';
Of course, it is possible to extract entries for any type of journal, including application journals.
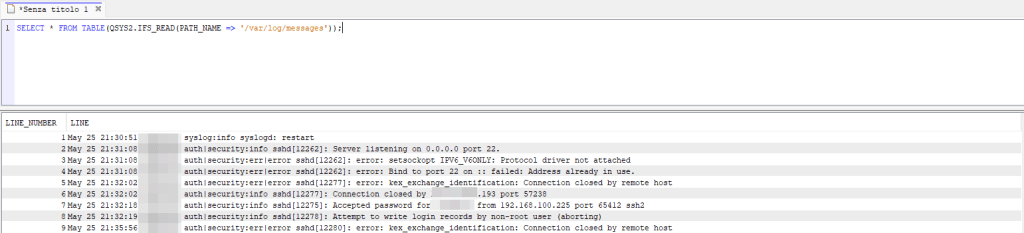
The last place that comes to mind is the system’s syslog service log file. In a previous article, we saw how this service could be used to log SSH activity. In my case the log file is located under /var/log/messages, so with the QSYS2.IFS_READ function I can read it easily: SELECT * FROM TABLE(QSYS2.IFS_READ(PATH_NAME => '/var/log/messages'));
These are just starting points… as mentioned previously, these entries are very important for monitoring events that occur on systems. Having them logged and stored in a single repository for other platforms can make a difference in managing attacks or system incidents in general.
Do you use these features to monitor and manage events on your systems?